在DeepSeek开源周的精彩进程中,第四天迎来了三大核心项目的亮相,旨在深度优化并行训练的效率。这三个项目分别是:DualPipe、EPLB和profile-data,它们共同构成了提升AI训练效能的关键拼图。
首先,让我们来探讨一下并行计算的概念。想象一下,一家餐厅突然迎来了100位顾客的用餐高峰。如果仅有一位厨师负责烹饪,那么任务将异常艰巨且耗时。但若有五位厨师同时工作,将菜单均匀分配,每位厨师负责一部分菜品,那么整体效率将显著提升。然而,这种分配方式也可能导致工作量的不均衡,比如一位厨师负责复杂的菜品,而其他厨师则相对轻松,这就是负载均衡问题。
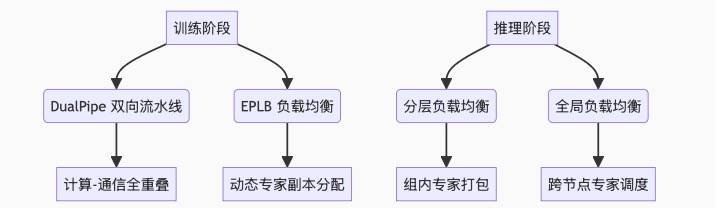
DeepSeek此次推出的开源项目,正是为了解决上述并行计算中的挑战,特别是负载均衡问题。DualPipe和EPLB这两个项目,可以形象地比喻为餐厅厨房的“智能流水线”和“动态菜谱分配器”。
DualPipe通过实现计算与通信的重叠,极大地提升了训练效率。就像餐厅中的切菜工和炒菜工协同工作,切完一道菜的食材后立刻传给炒菜工,同时开始准备下一道菜,实现了工作流程的无缝衔接。

而EPLB则专注于解决负载均衡问题。当某种复杂菜品(如佛跳墙)的订单激增时,系统会自动复制该菜谱并优先分配给空闲的厨师(GPU),从而避免个别厨师过度劳累,确保整体工作效率。

这两个技术的结合,使得DeepSeek AI在保持高效训练的同时,能够显著降低计算资源需求。相比竞争对手的方案,DeepSeek AI能够减少高达11倍的计算资源,从而避免了采购昂贵硬件集群的必要,降低了硬件开支和运维成本。这种资源优化技术,无疑是AI领域的重大突破。
在与OpenAI、Google、meta等科技巨头的竞争中,DeepSeek AI选择了“效率至上”的差异化战略。当这些巨头依赖天价的Nvidia H100集群来彰显实力时,DeepSeek却通过算法优化,将性能相对受限的H800 GPU转化为高效的算力单元。这种创新方法使得DeepSeek能够在仅使用1/5硬件资源的情况下,实现与竞争对手同等的训练突破。
DeepSeek的这一系列创新,不仅改变了算力竞赛的规则,还彰显了算法创新在AI领域的重要性。这不再是简单的硬件堆砌和蛮力比拼,而是智慧与创新的较量。DeepSeek正以其实力,重新定义着AI训练的未来。