英伟达近期震撼发布了Eagle 2.5视觉-语言模型,该模型专为大规模视频与图像的处理而设计,展现了卓越的多模态学习能力。在复杂的视觉与语言融合任务中,Eagle 2.5凭借其出色的性能,成为了业界的焦点。
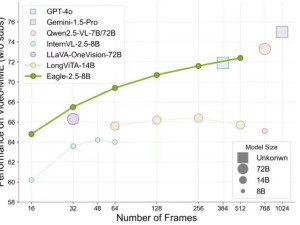
Eagle 2.5不仅擅长解析高分辨率图像,更在处理长视频序列时游刃有余。尽管其参数规模仅为80亿,但在Video-MME基准测试中,Eagle 2.5以72.4%的高分脱颖而出,这一成绩令人瞩目,甚至与参数量远超其上的Qwen2.5-VL-720亿和InternVL2.5-780亿等模型相媲美。
Eagle 2.5的成功背后,两大创新训练策略功不可没:信息优先采样与渐进式后训练。信息优先采样策略通过两项独特技术,进一步优化了模型的训练过程。
首先,图像区域保留(IAP)技术确保了超过60%的原始图像区域得以保留,有效避免了宽高比失真,从而保证了图像的完整性和真实性。其次,自动降级采样(ADS)技术根据上下文长度,智能地平衡视觉与文本输入,既保证了文本的完整性,又优化了视觉细节的呈现,使得模型在处理复杂场景时更加游刃有余。
而渐进式后训练策略,则是通过逐步扩展模型的上下文窗口,从32K到128K token,使模型能够灵活应对不同长度的输入。这一策略不仅增强了模型的泛化能力,还避免了模型对单一上下文范围的过拟合,确保了模型在各种情况下的稳定性能。
为了训练Eagle 2.5,英伟达整合了丰富的开源资源与定制数据集Eagle-Video-110K。该数据集专为理解长视频而设计,采用了独特的双重标注方式。自上而下的方法,通过故事级分割,结合人类标注的章节元数据和GPT-4生成的密集描述,为模型提供了宏观的叙事结构。而自下而上的方法,则利用GPT-4为短片段生成问答对,捕捉时空细节,为模型提供了微观的信息补充。
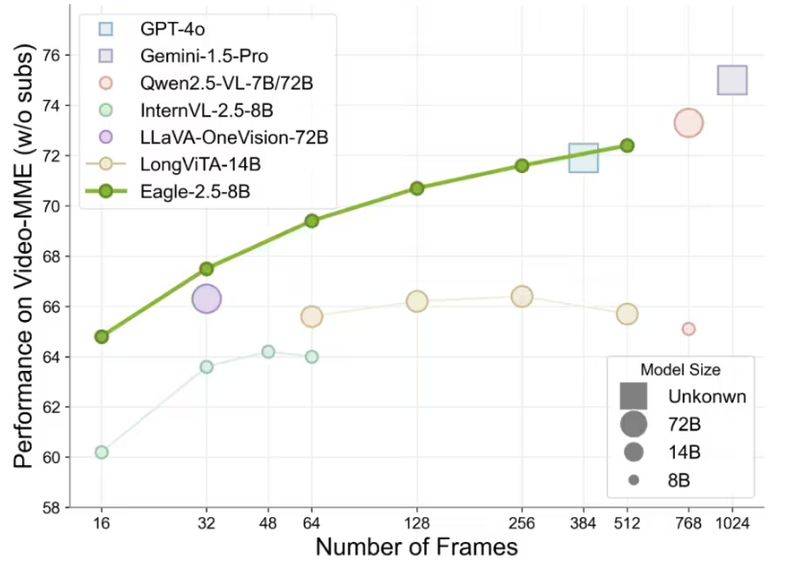
数据集还通过余弦相似度筛选,确保了数据的多样性和非冗余性。这一举措不仅提升了数据的叙事连贯性和细粒度标注质量,还显著增强了模型在高帧数(128帧)任务中的表现。Eagle 2.5在处理长视频和复杂图像时展现出的卓越能力,正是得益于这一精心设计的训练数据管道。