近日,DeepSeek在官方钦定的“开源周”内动作频频,已陆续开源四个项目,并在星期四最新发布了名为DualPipe的技术,该技术实现了计算与通信的双向并行处理。与此同时,DeepSeek还推出了一项别出心裁的举措——错峰定价。
在2月26日,DeepSeek宣布自即日起,于北京时间每日00:30至08:30的夜间空闲时段,推出错峰优惠活动。而就在前一天,DeepSeek才刚刚恢复了官方的API充值服务。此次优惠力度之大,令人瞩目。根据官方公告,在夜间空闲时段,DeepSeek API的调用价格将大幅下降:DeepSeek-V3降至原价的50%,而DeepSeek-R1更是低至25%(即降价75%)。
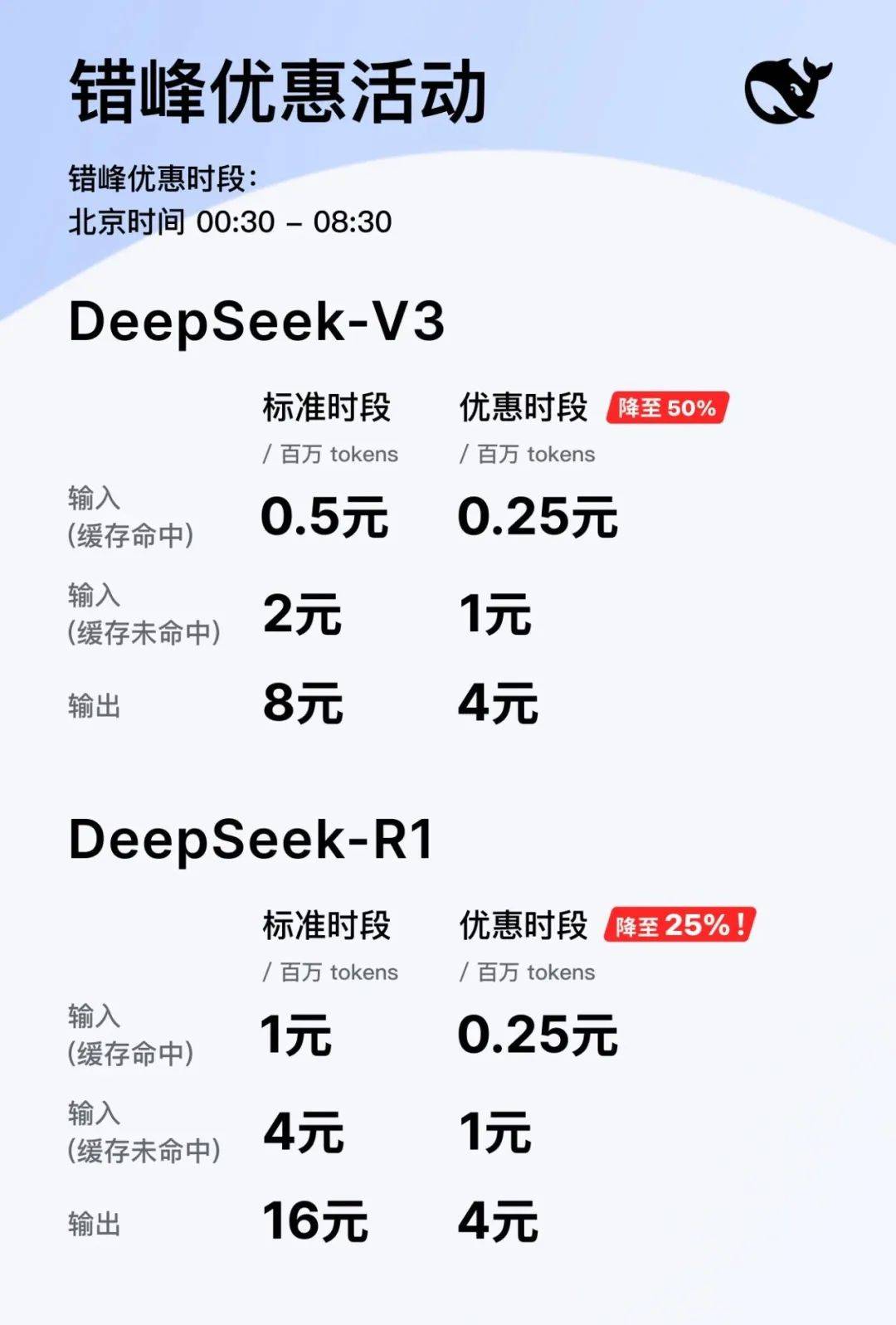
具体价格调整如图所示,DeepSeek此次的优惠力度无疑为开发者们带来了实质性的利益。值得注意的是,与DeepSeek-V3发布之初的“优惠体验期”有明确的时间期限不同,这次的错峰优惠仅有“时段限制”,而没有明确的“期限”。因此,我们可以将其视为一种长期的“错峰定价”策略。
DeepSeek-V3和DeepSeek-R1两款模型在优惠时段的价格也变得完全一致。输入(缓存命中)为0.25元/百万tokens,输入(缓存未命中)为1元/百万tokens,输出为4元/百万tokens。这一策略可能也是DeepSeek有意为之,旨在降低开发者使用DeepSeek-R1的成本顾虑,同时模糊两种模型的边界,鼓励开发者根据需求灵活调用。
DeepSeek此次调整最核心的变化在于采用了“错峰定价”的运营策略。这一策略的优势显而易见,很可能引发其他大模型如豆包、通义千问等的跟进,甚至可能再次掀起一场大模型价格战。回顾2024年初DeepSeek-V2发布后,就曾掀起过一场价格战。
事实上,DeepSeek-V3在之前已经有过降价历史。在其“优惠体验期”结束前,全时段的优惠价甚至比现在优惠时段的价格还要便宜。然而,DeepSeek-R1自发布以来价格一直未变。因此,此次DeepSeek-R1高达75%的“错峰降价”无疑给开发者们带来了更大的惊喜。
从能力上看,DeepSeek-R1的表现已经无需多言。无论是产品层面思维链的创新,还是工程层面实现的极致成本,都让DeepSeek-R1成为了当下备受瞩目的模型。降价策略无疑将进一步降低开发者调用成本和门槛,间接推动更好的AI体验在更多AI应用中推广。

以字节跳动旗下的豆包通用模型为例,其价格相较于DeepSeek在优惠时段的价格仍显偏高。甚至DeepSeek-R1官方满血版在优惠时段的价格,比32b蒸馏版还要更便宜。这不仅在国内市场具有竞争力,在海外市场也同样如此。DeepSeek-R1/V3在海外也推出了同样的运营策略,大幅降价50%和75%,优惠时段直接对应北京时间00:30至08:30,对于面向部分海外用户市场的开发者来说,具有更强的吸引力。
错峰定价本身并不新奇,类似于我们熟悉的错峰电价。DeepSeek官方在新闻稿中也表示,推出错峰优惠活动是为了鼓励用户充分利用这一时段,享受更经济、更流畅的服务体验。从开发者的角度来看,这种运营策略几乎百利而无一害;从大模型厂商和云计算平台的角度看,也是利大于弊,可以更大程度地利用服务器资源。
因此,目前来看,其他大模型跟进错峰定价的运营策略应该是题中应有之义。只是具体策略上可能会有所不同,比如需要考虑不同时区(不同用户市场)的问题。然而,DeepSeek此次举措是否会引发行业连锁反应,甚至复刻一年前的大模型价格战,仍有待观察。

回顾2024年5月初,DeepSeek发布了第二代MoE大模型DeepSeek-V2,并首次引入了多头潜在注意力(MLA)机制。更重要的是,其价格仅为当时ChatGPT主力模型GPT-4 Turbo的近百分之一,在性价比上直接秒杀了国内外一众大模型。此次DeepSeek在开源周展现出一系列能力,如长上下文的突破、芯片利用效率的提升等,未必不会是又一轮大模型价格战的“新开端”。