近期,一项创新的人工智能技术引起了广泛关注。据一项4月4日发布的最新研究显示,该技术采用了一种独特的递归架构,使得模型在推理过程中能够自我修正输出,极大地提升了准确性和效率。
这项名为SPCT的技术分为两个阶段实施。在第一阶段,即冷启动阶段,通过拒绝式微调,让模型适应不同类型的输入,并以正确的格式生成原则和点评内容。随后进入第二阶段,即基于规则的在线强化学习阶段,这一阶段采用规则奖励机制,鼓励模型生成更加精准的原则和点评,从而增强了推理阶段的可扩展性。
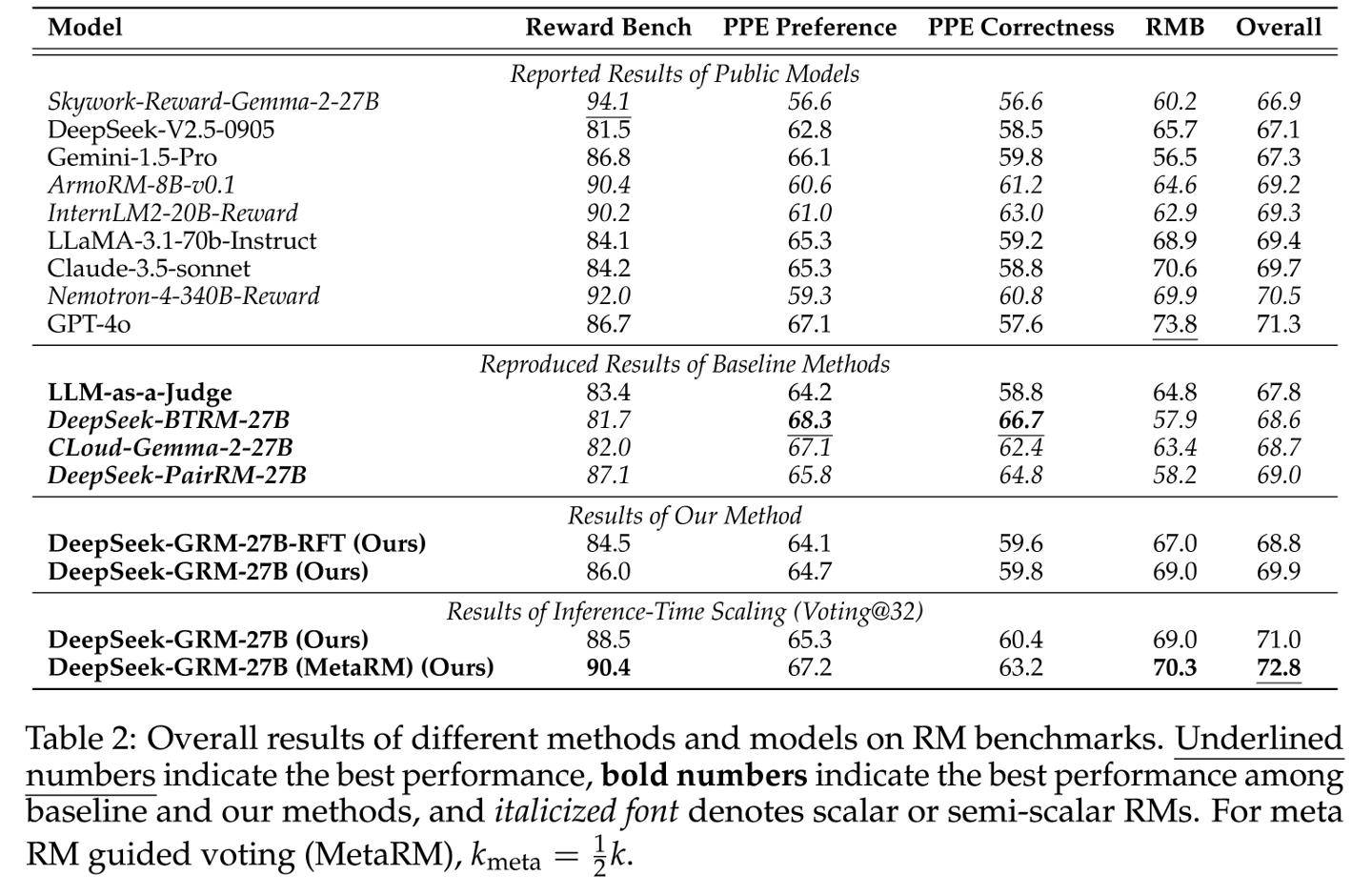
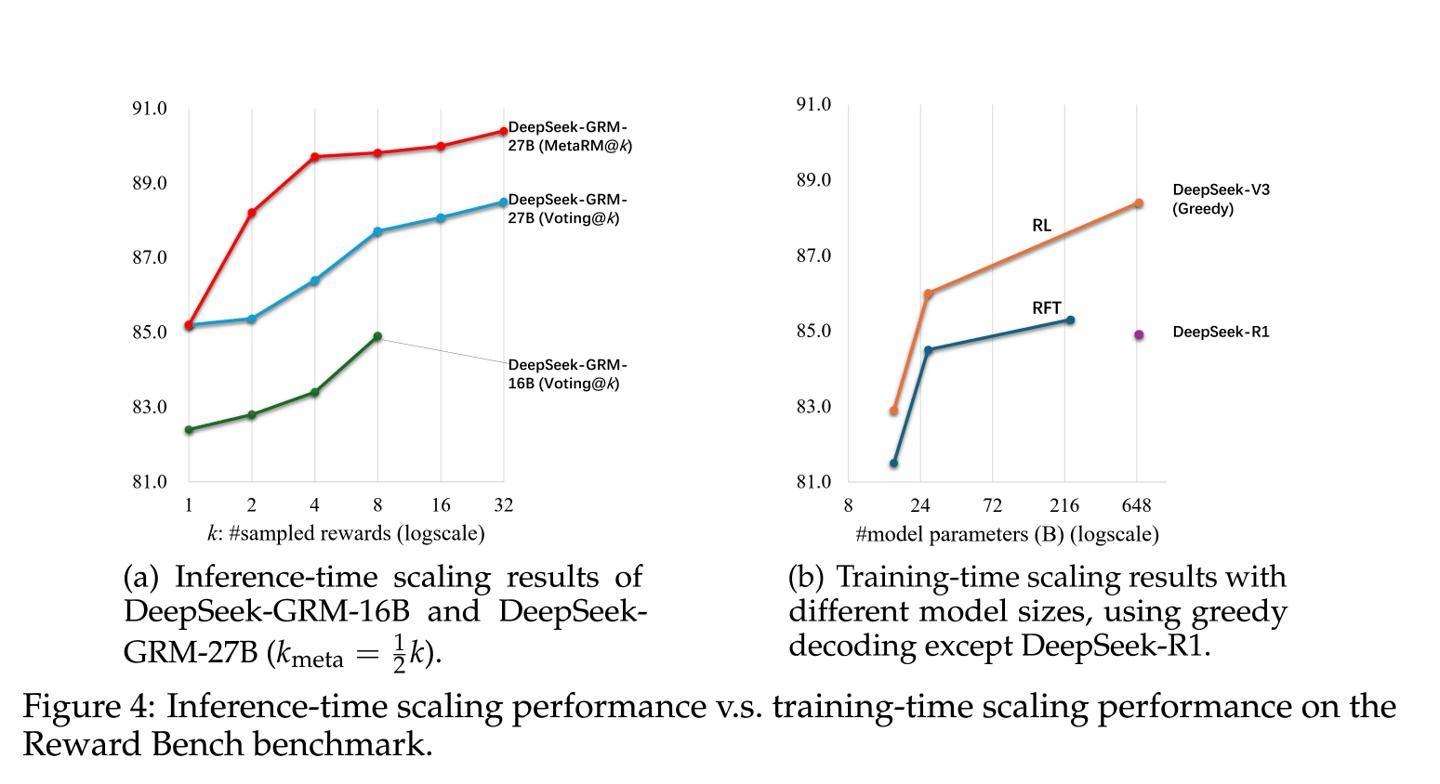
在实际测试中,使用了拥有270亿参数的DeepSeek-GRM模型。通过每查询32次采样的推理计算,该模型的表现达到了671B规模模型的性能水平。这一硬件感知设计融合了混合专家系统(MoE),支持高达128k token的上下文窗口,并且单查询延迟仅为1.4秒,表现出色。
研究报告进一步指出,SPCT技术显著降低了高性能模型的部署成本。以DeepSeek-GRM模型为例,其训练成本约为1.2万美元(按当前汇率约合87871元人民币),在MT-Bench测试中的得分高达8.35。相比之下,拥有340B参数的Nemotron-4模型需要120万美元的训练成本才能获得8.41的得分,而OpenAI的GPT-4o模型,尽管得分高达8.72,但其训练成本更是高达630万美元(按当前汇率约合4613.2万元人民币),是DeepSeek-GRM成本的525倍之多。
SPCT技术还带来了其他显著优势。据研究团队介绍,该技术减少了90%的人工标注需求,并且在能耗方面相比传统方法降低了73%。这一突破为实时机器人控制等动态场景提供了新的可能性,预示着人工智能技术在未来将有更加广泛的应用。